
How to reduce the gap between OLTP and OLAP graph solutions with Spark-Tinkerpop
By Fabiana Lanotte
OLTP versus OLAP graph solutions
Graphs are all around us. They can be made to model countless real-world phenomena ranging from the social to the scientific including engineering, biology, medical systems, IoT systems, and e-commerce systems. They allow us to model and structure entities (i.e. graph’s nodes) and relationships among entities (i.e. graph’s edges) in natural way. As an example, a website can easily be represented as a graph. In a simple approach one can model web pages as nodes and hyperlinks as relationships among web pages. Then, graph theory algorithms can be easily applied to extract new valuable knowledge. For example, by applying these algorithms on a website graph one can discover how information is propagated among nodes, or organize web pages in clusters having similar topics and strictly connected.
For this reason, in the last years graph databases have gained a lot a popularity. Differently from traditional relational databases (or other storage paradigms, such as document databases), graph databases store entities in terms of their direct relationships (e.g. adjacency matrix, incidence matrix, etc. ) instead of inferring connections among entities through costly join operations. This means that relationships are modeled in a graph database as first-class citizens.
Nowadays, different and complementary Big Data solutions have been developed for providing either on-line transaction processing (OLTP) or on-line analytical processing (OLAP) on graphs. OLTP systems are characterized by a large number of short on-line transactions which involve small portions of graph data (e.g. inserting new nodes or edges, simple queries, etc. ). The main emphasis of these solutions is put on very fast query processing and maintaining data integrity in multi-access environments, with effectiveness measured by number of transactions per millisecond. Titan, OrientDB, Neo4j are examples of OLTP tools. OLAP systems instead perform complex analysis (e.g. graph traversal, data aggregation) which involve extremely large graphs. Spark GraphX, Apache Giraph and SparkGraphComputer are examples of OLAP tools.
Although OLTP and OLAP tools represent fundamental components for the Big Data field, existing infrastructures are not yet mature enough to integrate OLAP systems with OLTP graph solutions.
In this post, we present Spark-Tinkerpop, a Scala API for converting a graph database, such as Titan, Neo4J, OrientDB or GraphSON database, into a GraphX format, and viceversa. It represents a further layer of abstraction on top of Tinkerpop which is necessary for bridging the gap between the various graph-vendor implementations and the intended underlying Spark implementations. All that Spark-Tinkerpop needs is to define a bijection function to convert the Spark vertices’s and edges’ types into a Map[AnyRef]
Spark-Tinkerpop
In the following we show a snapshot of the object TitanGraphProvider which provides ‘native’ communications between Spark and Titan. This connector, by-passing some of the Tinkerpop APIs, is able to write/read data with the underlying graph engine.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
class SimpleEventConverter extends ** * The Titan-specific implementation of the `TinkerGraphProvider`, providing also native load and save functions. * Additionally, this provider also exposes a function that wraps a closure onto a `Management` instance to allow * for certain operations as table and schema creation. */ object TitanGraphProvider extends NativeTinkerGraphProvider with TitanResourceConfig with HadoopGraphLoader with Serializable { /** * Opens a `Management` instance and applies `f`, committing the transaction and the end in case of success, and * rolling back in case of failure. * @param f the function to applu on the fresh `Management` instance */ def withGraphManagement[U](f: TitanManagement => U) = { val management = graph.openManagement() Try { f(management) } match { case Success(u) => management.commit(); graph.tx.close(); u case Failure(e) => management.rollback(); graph.tx.close(); throw e } } /** * Shuts down and truncates the graph. Note that this is a point of no return: the graph cannot be used beyond * this point. */ def clearGraph() = Try { log.warn("Shutting down graph instance...") graph.close() log.warn("Clearing graph...") TitanCleanup.clear(graph) } /** *Save a GraphX instance into Titan **/ def saveNative[A, B](rdd: RDD[TinkerpopEdges[A, B]], useTinkerpop: Boolean = false)(implicit arrowV: Arrows.TinkerRawPropSetArrowF[A], arrowE: Arrows.TinkerRawPropSetArrowF[B]) = { ... } /** *Load a Titan graph and convert it into GraphX format **/ def loadNative[A, B](implicit provider: NativeTinkerGraphProvider, arrowV: Arrows.TinkerVertexArrowR[A], arrowE: Arrows.TinkerEdgeArrowR[B], A: ClassTag[A], B: ClassTag[B]) = SparkBridge.asGraphX[A, B] { provider.loadNative(sparkContext) } }{ ... } |
Lets try a simple example of usage.
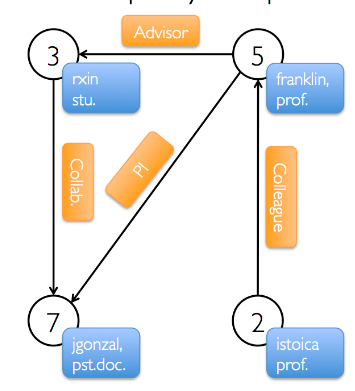
Suppose we have a GraphX graph of connected people as described here and we want to store it as a Titan graph.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
case class Person(id:Long, name: String, role: String) case class Relationship(src:Long, dst: Long, rName: String) def createGraphxGraph(sc: SparkContext): Try[Graph[Person, Relationship]]= { val users: RDD[(VertexId, Person)] = sc.parallelize( Array( (3L, Person(3L, "rxin", "student")), (7L, Person(7L, "jgonzal", "postdoc")), (5L, Person(5L, "franklin", "prof")), (2L, Person(2L, "istoica", "prof")))) // Create an RDD for edges val relationships: RDD[Edge[Relationship]] = sc.parallelize( Array( Edge(3L, 7L, Relationship(3L, 7L, "collab")), Edge(2L, 5L, Relationship(2L, 5L, "colleague")), Edge(5L, 3L, Relationship(5L, 3L, "advisor")), Edge(5L, 7L, Relationship(5L, 7L, "pi")))) // Build the initial Graph Try{Graph(users, relationships)} } |
As said before, the only thing we need is to define a conversion strategy for translating the types Relationship (i.e. GraphX edges) and Person (i.e. GraphX vertices) into a Map types. For this reason, we define the classes RelationshipRawPropSetArrow and RelationshipPropSetArrow for converting a Relationship type into a TinkerPropMap[AnyRef]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
sealed class RelationshipRawPropSetArrow extends Arrows.TinkerRawPropSetArrowF[Relationship] with Arrows.TinkerRawPropSetArrowR[Relationship] { def apF(r: Relationship) = Map( "src" -> r.src.asInstanceOf[AnyRef], "dst" -> r.dst.asInstanceOf[AnyRef], "rName" -> r.rName) def apR(map: Map[String, AnyRef]) = Relationship( map("src").asInstanceOf[Long], map("dst").asInstanceOf[Long], map("rName").toString ) } sealed class RelationshipPropSetArrow(implicit arrowF: Arrows.TinkerRawPropSetArrowF[Relationship], arrowR: Arrows.TinkerRawPropSetArrowR[Relationship]) extends Arrows.TinkerPropSetArrowF[Relationship, AnyRef] with Arrows.TinkerPropSetArrowR[Relationship, AnyRef] { def apF(a: Relationship): TinkerPropMap[AnyRef] = Arrows.tinkerPropSetArrowF(arrowF).apF(a) def apR(b: TinkerPropMap[AnyRef]): Relationship = Arrows.tinkerPropSetArrowR(arrowR).apR(b) } |
and the classes PersonRawPropSetArrow and PersonPropSetArrow for converting Person instances:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
sealed class PersonRawPropSetArrow extends Arrows.TinkerRawPropSetArrowF[Person] with Arrows.TinkerRawPropSetArrowR[Person] { override def apF(a: Person): Map[String, AnyRef] = Map("id" -> a.id.asInstanceOf[AnyRef], "name" -> a.name, "role" -> a.role ) override def apR(b: Map[String, AnyRef]): Person = Person(b("id").asInstanceOf[Long], b("name").toString, b("role").toString) } /** * Convert a Person type into A TinkerPopMap and viceversa * @param arrowF * @param arrowR */ sealed class PersonPropSetArrow(implicit arrowF: Arrows.TinkerRawPropSetArrowF[Person], arrowR: Arrows.TinkerRawPropSetArrowR[Person]) extends Arrows.TinkerVertexPropSetArrowF[Person, AnyRef] with Arrows.TinkerVertexPropSetArrowR[Person, AnyRef] { override def apF(a: Person): TinkerVertexPropMap[AnyRef] = Arrows.tinkerVertexPropSetArrowF(arrowF).apF(a) override def apR(b: TinkerVertexPropMap[AnyRef]): Person = Arrows.tinkerVertexPropSetArrowR(arrowR).apR(b) } |
After defining the previous classes, we can include an instance of those as implicit variables in an object GraphArrow; it will contain all the implicit parameters required by TitanGraphProvider for the conversion process.
|
1 2 3 4 5 6 7 8 9 10 11 |
object GraphArrow extends Serializable { implicit val rawPersonPropSetArrow = new PersonRawPropSetArrow implicit val rawRelationshipPropSetArrow = new RelationshipRawPropSetArrow implicit val personTinkerPropSetArrow = new PersonPropSetArrow implicit val relationshipTinkerPropSetArrow = new RelationshipPropSetArrow implicit val personTinkerVertexArrow = Arrows.tinkerVertexArrowR(personTinkerPropSetArrow) implicit val relationshipTinkerVertexArrow = Arrows.tinkerEdgeArrowR(relationshipTinkerPropSetArrow) } |
Finally we create a main class which uses TitanGraphProvider and GraphArrow
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import GraphArrow._ import org.cgnal.graphe.tinkerpop._ object Example{ case class Person(id:Long, name: String, role: String) case class Relationship(src:Long, dst: Long, rName: String) implicit def provider = TitanGraphProvider def createGraphxGraph(sc: SparkContext): Try[Graph[Person, Relationship]]= { val users: RDD[(VertexId, Person)] = sc.parallelize( Array( (3L, Person(3L, "rxin", "student")), (7L, Person(7L, "jgonzal", "postdoc")), (5L, Person(5L, "franklin", "prof")), (2L, Person(2L, "istoica", "prof")))) // Create an RDD for edges val relationships: RDD[Edge[Relationship]] = sc.parallelize( Array( Edge(3L, 7L, Relationship(3L, 7L, "collab")), Edge(2L, 5L, Relationship(2L, 5L, "colleague")), Edge(5L, 3L, Relationship(5L, 3L, "advisor")), Edge(5L, 7L, Relationship(5L, 7L, "pi")))) // Build the initial Graph Try{Graph(users, relationships)} } def storeInTitan(graph: Graph[Person, Relationship]) = Try { graph.saveNativeGraph(false) } private def createTitanSchema() = Try { TitanGraphProvider.withGraphManagement { m => m.createVertexLabel("Person") { _.partition() } m.createEdgeLabel("Relationship") { _.multiplicity(SIMPLE) } m.createPropertyKey[String]("name") { _.cardinality(SINGLE) } m.createPropertyKey[String]("role") { _.cardinality(SINGLE) } m.createPropertyKey[String]("rName") { _.cardinality(SINGLE) } } } def loadFromTitan(sc: SparkContext): Try[Graph[Person, Relationship]] = Try {sc.loadNative[Person, Relationship]} def main(args: Array[String]): Unit = { // Assume the SparkContext has already been constructed val sc: SparkContext def run = for { graphX Try {println("Graphs converted with success!") }, error => { TitanGraphProvider.clearGraph(); Failure(error) } ) sc.stop() } |
That’s it. By playing with this API one can combine the high scalability of the Titan graph database with a powerful and resilient graph computing system such as GraphX.